Overview
You have searched for a particular phrase but the document you expect to get in return is very low in the results. You would like to know if the search string or number of views is more important for search results to appear in the top search result.
Information
The relevance rank is calculated as follows:
Rank = (Similarity Score + Proximity Score) * Outcome Type * Object Type * Recency * Social Score
The following sections detail the above variables and their impact on the rank of a content item.
Similarity Score
When searching for a phrase, the system looks at each word and checks the match type and place. Each match type and place has its boost score. The default settings are listed in Table 1.
The boost score is normalized with:
- The number of times the searched term appears in the given content (the more it appears, the better)
- The number of times the searched term appears in the search index (the more common the term is, the less impact it has on the rank)
Match types that Cloud Search employs:
- Raw: Exact matches of the search term
- Analyzed: Matches that are created by language analyzer using stemming
- Edgengram: Partial match, used for wildcard search matches and matches in search-as-you-type queries
Places of matches that Cloud Search employs:
- Subject: Title field of content items
- Body: Content of content items
- Tags: Tags added to content items
| Match Type | Match Place | ||
| Subject | Body | Tags | |
| Raw | 1.0 | 0.1 | 0.5 |
| Analyzed | 1.0 | 0.1 | |
| Edgengram | 1.0 | 0.1 | 0.5 |
Proximity Score
The proximity score checks how close is the term the user searches for to what appears in the content. When a user searches for a phrase built from several words, this phrase may appear the same way in the content, or it may appear in the content in a slightly different way. For example, content with the term "product one-pager brochure" is an approximate match when searching for "product brochure".
Types of proximity boosts:
- Exact match: When all the search terms appear in the content next to each other
- Proximity match: When all the search terms appear less than three words apart from each other
The default settings are below.
| Place | Proximity Boost | Exact Match Boost |
| Subject | 0.5 | 1.6 |
| Body | 0.5 | 1.0 |
| Tags* | 0.1 | 1.0 |
* Having proximity score on Tags is unlikely to happen.
Higher the boost value matches in the given field, and match method gets ranked higher.
Additionally, frequency is taken into account, i.e., how many occurrences of the word user is searching for exists in the field. For example, if a 20,000-word essay makes a single reference to the movie "Finding Nemo" somewhere in the document and another document in the system has only 50 words and includes "Finding Nemo", the latter is counted more relevant to a query for "nemo".
Outcome Type
Content in Jive can be marked with structured outcomes. These outcomes impact the score of that content in the search results; results are boosted based on outcome type.
The boosts given to content according to outcome type are listed below.
| Outcome | Boost | Outcome | Boost |
| Finalized | 1.4 | Official | 2.0 |
| Outdated | 0.1 | Default | 1.0 |
This score is being multiplied by the boosts above.
Note that a higher boost results in that content being ranked higher in the search results, so the 0.1 score for outdated documents significantly reduces its rank.
Object Type
Similarly to outcome boost, there is a boost for ranks based on the type of content used. Documents and blogs are ranked higher in the search results as these are usually used for more comprehensive content that may be more relevant for the searching user. The settings are listed below.
| Object | Boost | Object | Boost |
| Document | 1.4 | Poll | 1.0 |
| Blog | 1.4 | Idea | 1.0 |
| Discussion | 1.0 | Video | 1.0 |
| Question | 1.0 | Status Update | 1.0 |
Recency
Recency (or time decay) lowers the score for older content. The impact of content can be seen this way:
Figure: Recency boost by default
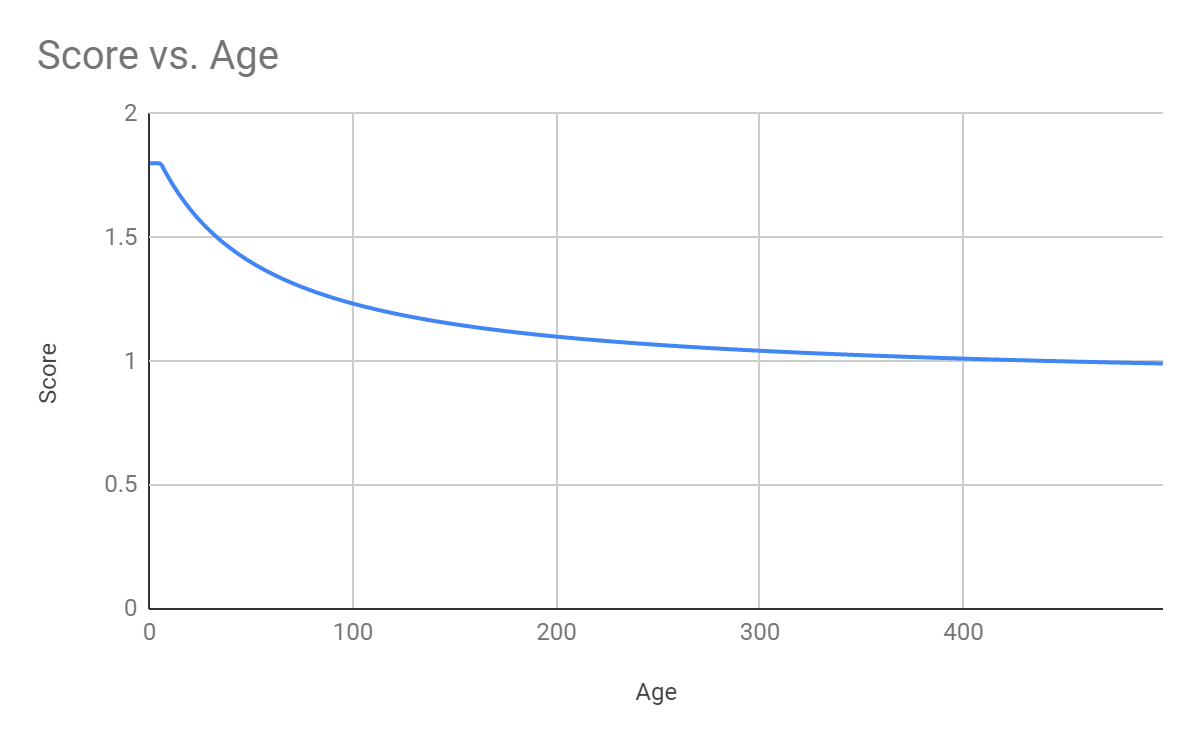
Recency score calculation is based on the following parameters:
| Parameter | Description | Default |
| Drop speed | Determines how fast the algorithm reduces the content score by age | 50 |
| Max value | Determines the latest period the content from which has the same score without decay | Four weeks |
| Minimum score | Determines the score difference of a very old document and a just created one as two times as maximum. It is set so that even the oldest relevant content can be found but allows preference for fresh content. | 0.9 |
Social Score
The Jive R2E2 service calculates a social score for the search phrase based on given user activities, follows, and other behavioral connections.
The R2E2 service (previously Jive Find) provides improved search relevance by incorporating social information into search. Search rankings are tailored for individuals based on dynamic signals derived from activity within Jive. As users use Jive, data is generated about activities, such as views, creates, responses, and likes. These activities are processed in the Jive Recommender service and summarized into a form that can be used by Jive Search to enhance the relevance of the search results. When a user searches for content (or places), items considered close to the user are given a boost in the search rankings. This boost is based on the activities performed by the user or other individuals connected to the user. This personalizes search results for each user.
The details of how user activity translates into levels of boost change over time as the system is optimized.
Priyanka Bhotika
Comments